AI Info Transport Distribution: Toward the Edge
Analysts
Ray Mota
Introduction
Artificial Intelligence (AI) systems, especially the fast-evolving neural net-based large language models (LLM), are resource hogs as their billions (or even trillions) of parameters are trained with data using machine learning. Training an LLM can take billions of kilobytes of data that must be gathered, cleaned, put in usable form, and fed into the model.
Most of these models are being trained on centralized computing resources with specialized processors, moving the data as needed mostly between centralized data centers. Zayo and Lumen recently reported significant demand for dark fiber, with Zayo indicating that customers are requesting counts from 144 to 432 fibers[1]. Cisco indicated that Ethernet connectivity sales to AI data centers is an “emerging opportunity.” Other major industry players such as Nokia and Arista are also investing in similar capabilities[2]. This is also in line with the majority of AI use cases today where AI agents are being trained largely on common data sets with some proprietary data.
However, this is very likely to change as AI utilization becomes more ubiquitous, more distributed, and more democratized.
How AI Is Evolving
More ubiquitous: As organizations realize the capabilities of AI and gain expertise in using it in the organization, and as AI becomes multimodal and Agentic AI inches closer to reality, the use of AI is growing tremendously as are its data, compute, and transport requirements.
More distributed: Increasingly, companies are developing their own AI agents and co-pilots and training them on proprietary data. For example, in healthcare, strict rules around protecting personal health information may drive healthcare organizations to use locally trained AI models. More distributed AI is also driven by hardware innovation and an increase in compute power that improves performance. In fact, many companies are now relying on distributed cloud computing for their AI applications.
More democratic: What we learned from the recent emergence of DeepSeek is that the cost of training of AI models will become less expensive, therefore more democratized, paving the way for broader adoption, and enabling training to become more distributed. Furthermore, many newer versions will also not require the vast processing power of the specialized processors (such as the NVIDIA GeForce RTX 5090 GPU processor). These changes will lead to the Jevons Paradox[3], also known as Jevons effect, where technological advancements make a resource more efficient to use, leading to cost reduction, which results in even more resource consumption (in this case more AI use).
The Effect
As shown in Figure 1, processing today is mostly centralized into massive data centers on very specialized hardware and software platforms. But it will move out toward the far edge on the X-axis (the distribution across centralized, regionalized, metro, local, and far edge is a matter of discussion and further research).
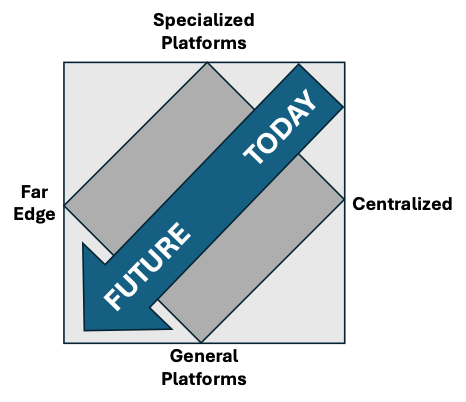
Implications for Telcos and Cable Operators
As AI utilization grows and becomes more specialized and distributed, the current model of centralized computing will evolve to a more distributed compute architecture with a significant amount of processing happening at the far edge, particularly for very data intensive applications such as video training and so on. This will benefit telcos and other access players such as cable operators that have data centers and other compute resources closer to the edge of the network.
Where the computing and storage are done will depend upon both the evolution of the AI and processing technology and the particular applications. For instance, many have touted the benefits of running AI based video processing on near-edge computing platforms provided by a CSP.
ACG Research continues to follow these developments. If the technology and usage predictions are right, AI training and running will require much more bandwidth in local and metro areas as well as opportunities for telcos and cable operators to provide nearby computing platforms.
Liliane Offredo-Zreik and Mark Mortensen are both principal analysts with ACG Research. They can be reached at loffredo@acgcc.com and mmortensen@acgcc.com
[1]https://www.fierce-network.com/broadband/zayo-says-its-new-ai-demand-was-long-time-coming?utm_medium=email&utm_source=nl&utm_campaign=FN-NL-FierceNetworkBroadband&oly_enc_id=5789F4279956B4Z
[2]https://www.lightreading.com/ai-machine-learning/buoyed-by-ai-cisco-sees-lots-of-telcos-planning-edge-rollouts?utm_source=eloqua&utm_medium=email&utm_campaign=SP_News_LightReading_Weekly_NL_20250213&sp_cid=10434&utm_content=SP_News_LightReading_Weekly_NL_20250213&sp_rid=7228622&sp_aid=14935&sp_eh=72c9c7f864fa77af729669640f61d809260f928933785ac000dcc123d47a89b2
You might like similar








